Data Science In the Balanced Team
By Ian
 This year I was fortunate enough to speak at PyCon Ireland 2016 in Dublin. This was a great event with lots of interesting Python based talks and a full PyData track over the two days. The topic of my talk was something I’ve been thinking about a lot over the last few years: how data scientists can work with other disciplines.
This year I was fortunate enough to speak at PyCon Ireland 2016 in Dublin. This was a great event with lots of interesting Python based talks and a full PyData track over the two days. The topic of my talk was something I’ve been thinking about a lot over the last few years: how data scientists can work with other disciplines.
Recently designers and product managers have begun working more closely with development teams, and in my opinion there are many lessons that data scientists can learn from this experience. In particular the concept of a “Balanced Team” appeals to me as a template for data scientists.
The slides for this talk are on SpeakerDeck, and the video is also available. In this post I want to recap my argument from the talk with some extended notes.
From Imposter Syndrome to Team Player
 I work as a data scientist at Pivotal Labs helping clients, often large enterprises, to bring data science into their business. However, I really started working with data when I was an academic, handling results from numerical simulations of the early universe.
I work as a data scientist at Pivotal Labs helping clients, often large enterprises, to bring data science into their business. However, I really started working with data when I was an academic, handling results from numerical simulations of the early universe.
 David Whittaker’s Imposter Syndrome post
David Whittaker’s Imposter Syndrome post
For a lot of people in academia, the concept of imposter syndrome is very familiar, and for me academia was a long process of dealing with imposter syndrome. This is the idea that you aren’t really good enough to be here and someday someone is going to figure it out. This post by David Whittaker captures what is really happening. Though you may think everyone knows more than you, really you are just observing the combined knowledge of a lot of different people.
As an academic it was easy to think that others in my field or outside in industry must be handling these data problems in a better way. I had done some formal computer science training in my undergrad degree, but I’d taught myself how to use scientific Python tools and software carpentry practices.

When I left academia to work as a data scientist my first steps were working on solo projects where I was often expected to be a data science unicorn. These type of projects involve a lot of pressure and the full weight of stakeholder expectations rests solely on you. It’s not a comfortable position to be in. Due to the hype around data science there was very little understanding by business stakeholders of the exploratory nature of much data science work, where positive results are not a guaranteed.
[By the way, the Data Science Unicorn is a real account, with a collection of data science learning material gathered by Jason Byrne.]
 Working solo on projects is very draining, so more recently I’ve been fortunate to find myself working at Pivotal in teams including developers, product designers and product managers. We opened our Dublin office last year on Back To The Future Day, hence the branded De Lorean, and we are always looking for people with empathy to join us.
Working solo on projects is very draining, so more recently I’ve been fortunate to find myself working at Pivotal in teams including developers, product designers and product managers. We opened our Dublin office last year on Back To The Future Day, hence the branded De Lorean, and we are always looking for people with empathy to join us.
Working as part of a team has been great, and I’ve been able to learn a lot about how modern software is built. In particular I’ve been interested in how disciplines like design and product management have been integrated with more traditional development including a concept called the “Balanced Team”.
Balanced Team
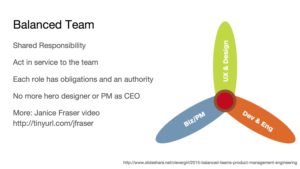 *Image from Janice Fraser's slides*
*Image from Janice Fraser's slides*
The idea for Balanced Team came from conversations between developers and product teams who had been working in an agile methodology but were seeing problems integrating design and product management. As I understand it, the main idea behind Balanced Team is to share responsibility between the team and make sure everyone is acting in service to the team, not just their own self interest. Janice Fraser played a central role in formulating these ideas and explains them in more detail in this talk.
This image from her slides shows that the main roles represented in a balanced team are development, design and product management. Each role has obligations and an authority which they bring to any interactions. Fraser describes Balanced Team as more of a work environment than a methodology, essentially a frame of mind about how the team should interact.
In the past product designers have been kept entirely separate from development teams, often in specialised design agencies. They were frequently required to act as “hero designers”, unable to admit any faults and working hard in crunch mode to meet deadlines. It was striking for me to see the similarities with the expectations on data science unicorns. Some of the goals of Balanced Team are to get away from this notion of hero designers, to reduce power struggles and allow more space for people to speak freely and discard failing solutions.
 Text from Janice Fraser’s slides
Text from Janice Fraser’s slides
In her talk Fraser describes the obligations and authority for each of the roles. For example the designer in the team needs to be the “empathizer-in-chief”, who understands the customer at an expert level, and can translate their high-value needs into product decisions. Their obligations to the team include honing their craft (as a service to the team) and facilitating balance between other parties within the team. Their main authority is the prioritisation of customer problems in every product conversation.
 Monica Rogati’s ‘data thinking’ post
Monica Rogati’s ‘data thinking’ post
It’s worth noting that as it is currently formulated, the Balanced Team concept does not include any data oriented role. Monica Rogati described what happens in this situation in her recent post on “data thinking”. Rogati talks about how Apple’s Photos product can identify faces in your photo collection and highlights a list of 5 of these people in alphabetical order. Depending on their name, this means your closest friends and family might not appear in the top 5 listing, despite perhaps appearing in most of your photos.
As Rogati describes, a simple application of data thinking, with no complex machine learning or predictive analytics, would reorder these photos in frequency order. The take-away recommendation is that to avoid these product mistakes “you need data thinking to be part of the culture and top of mind, not an after-thought.”
Things that worked
With this in mind, as a data scientist, I wondered how I would describe my obligations and authority. I've been fortunate to have worked over the last two years in teams with developers, designers and PMs, and in this time we've tried different approaches to bringing data science into this process. I'm going to describe some of the approaches that worked for us, some that didn't, and then try to distill what I've learned into a similar form to Janice Fraser's blueprint.
 User research seeks to find the right direction to head in the space of possible products. As part of a balanced team the data scientist has an obligation to use available data to inform lines of questioning for in-person interviews, validate the results of these interviews and identify gaps when interviewees are not representative. It’s great to observe these user interview sessions as a data scientist, because I always come out with a long list of questions to answer from the data.
User research seeks to find the right direction to head in the space of possible products. As part of a balanced team the data scientist has an obligation to use available data to inform lines of questioning for in-person interviews, validate the results of these interviews and identify gaps when interviewees are not representative. It’s great to observe these user interview sessions as a data scientist, because I always come out with a long list of questions to answer from the data.
A data scientist can also guide user research questions in order to understand the type of predictive models that will be suitable, answering questions about how much ‘explanability’ is needed, and where the line is between useful & creepy for instance.
 If your product manager has not worked with a data scientist before, you need to make a big effort to help them understand how you can contribute to the product. If they don’t understand how machine learning and predictive analysis can be effectively used, they will not direct the product discussion to include them.
If your product manager has not worked with a data scientist before, you need to make a big effort to help them understand how you can contribute to the product. If they don’t understand how machine learning and predictive analysis can be effectively used, they will not direct the product discussion to include them.
As part of a balanced team you have an obligation to be part of all product conversations and story generation and to proactively suggest where data thinking could be most effective. Don’t wait for someone to come to you with an idea ‘perfect for some data science’.
 Expanding this idea of education, your team will make most effective use of data when ‘data thinking’ is central to the culture and practices of the team. If they have not been exposed to this before you will need to educate and involve them in understanding the available data and analysis techniques you are using. Pairing goes some way to sharing this knowledge, and you can also consider having a ‘show & tell’ to describe data discoveries and explain the moving parts of the model you are building.
Expanding this idea of education, your team will make most effective use of data when ‘data thinking’ is central to the culture and practices of the team. If they have not been exposed to this before you will need to educate and involve them in understanding the available data and analysis techniques you are using. Pairing goes some way to sharing this knowledge, and you can also consider having a ‘show & tell’ to describe data discoveries and explain the moving parts of the model you are building.
As part of a balanced team, you have an obligation to educate your team about the techniques you’re using, the data that is available and what choices you have made in your analysis. The goal is not scrutiny of your work, but building confidence in your approach and results.
 At Pivotal we think Pair Programming is the best way to get fast feedback cycles and share knowledge. Data science is no different and we pair as data scientists when possible. We also like to pair with developers and designers to share knowledge of our methods and also get a new perspective on what we are building.
At Pivotal we think Pair Programming is the best way to get fast feedback cycles and share knowledge. Data science is no different and we pair as data scientists when possible. We also like to pair with developers and designers to share knowledge of our methods and also get a new perspective on what we are building.
Pairing with developers is particularly useful to continue the journey from exploratory analysis to production code.
Things that did not work
 Now let's consider a few things that we've tried, or experienced as part of a team in the past.
Now let's consider a few things that we've tried, or experienced as part of a team in the past.
 In one project we tried to keep our user stories unified from front to backend so overall user value would be apparent. This means that whenever we deliver a story we know that we’ve put together everything necessary for the user to benefit from this feature. Unfortunately it proved quite difficult to work with these large stories in practice.
In one project we tried to keep our user stories unified from front to backend so overall user value would be apparent. This means that whenever we deliver a story we know that we’ve put together everything necessary for the user to benefit from this feature. Unfortunately it proved quite difficult to work with these large stories in practice.
For one thing, having a single scale for estimation proved difficult to work with and our stories soon became too big to reliably show incremental progress to stakeholders, increasing communication difficulties. We eventually moved to having separate backlogs, which we already had for design work, although this means extra effort needed to keep backlogs in sync.
As part of a balanced team, the data scientist will need to take part in conversations about the engineering backlog (as well as design), and the PM will need to have a good handle on the inter-dependencies between backlogs.
 There’s sometimes a tendency to think data scientists should only arrive on a project once an MVP is built and some (usually limited) data is being collected. Even when machine learning is going to be at the core of a product, such as predictive maintenance, there’s sometimes a reluctance to bring data scientists/ML engineers in early on during the product creation phase.
There’s sometimes a tendency to think data scientists should only arrive on a project once an MVP is built and some (usually limited) data is being collected. Even when machine learning is going to be at the core of a product, such as predictive maintenance, there’s sometimes a reluctance to bring data scientists/ML engineers in early on during the product creation phase.
This denies the data scientist the chance to be involved in the early conversations about the feasibility of different product directions, give advice on what early instrumentation to include, and provide context using any existing data sets in the business. As part of a balanced team, I think it’s clear that data scientists can contribute from the very beginning of the project and should ask to join the early product creation.
 As expensive and expert resources there is a tendency to spread data scientists across multiple projects to maximise their effectiveness. Continually switching contexts and juggling multiple simultaneous top priorities makes this path more inefficient for team progress as a whole. This lesson has been learned with designers, product managers and others, but now seems to need to be learned again for data scientists.
As expensive and expert resources there is a tendency to spread data scientists across multiple projects to maximise their effectiveness. Continually switching contexts and juggling multiple simultaneous top priorities makes this path more inefficient for team progress as a whole. This lesson has been learned with designers, product managers and others, but now seems to need to be learned again for data scientists.
Being part of a balanced team means putting the team’s success first, which means being available and focused on a single team, a single product. This can result in what feels like inefficient use of your time if you’re not occupied 100%, but the alternative cost to the team of not having you available at the right moment is more detrimental. One way to justify this perceived inefficiency is to calculate the time & money wasted by a development team waiting for their shared data scientist to become available. Often what could have been a simple ten minute conversation can instead turn into days of emails, conference call scheduling and meeting planning, all because the data scientist is juggling other projects.
 There is so much hype around data science that it can feel like management expect the addition of a data scientist to instantly solve all existing problems. This is a dangerous situation to get into, and you must work to manage expectations, especially when starting to work on a new problem with many uncertainties. As part of a balanced team, the data scientist has a responsibility to inform the team’s expectations, and gains by sharing the burden of communicating and managing expectations with outside stakeholders.
There is so much hype around data science that it can feel like management expect the addition of a data scientist to instantly solve all existing problems. This is a dangerous situation to get into, and you must work to manage expectations, especially when starting to work on a new problem with many uncertainties. As part of a balanced team, the data scientist has a responsibility to inform the team’s expectations, and gains by sharing the burden of communicating and managing expectations with outside stakeholders.
 I hope our experiences can help you as you explore the idea of including data science in your balanced product teams. There are many things that could be part of the core obligations of a data scientist in the framework that Janice Fraser describes for a Balanced Team. For me, the data scientist should be the “voice of data” on the team. They should provide deep expertise and understanding about the available data, and be able to identify potential valuable uses and techniques.
I hope our experiences can help you as you explore the idea of including data science in your balanced product teams. There are many things that could be part of the core obligations of a data scientist in the framework that Janice Fraser describes for a Balanced Team. For me, the data scientist should be the “voice of data” on the team. They should provide deep expertise and understanding about the available data, and be able to identify potential valuable uses and techniques.
More and more we are seeing the implications of unethical uses of data and the data scientist should have the obligation to guard against unjustified (legally and mathematically), unethical and inappropriate uses of data. On the other hand where data is not currently being collected or is insufficient for future uses, the data scientist has an obligation to the team to begin collecting data to facilitate expected future product goals. In addition, data scientists can also facilitate balance in the team. Were I to include another obligation, it would be to “hone your craft” as Janice Fraser describes explicitly for designers.
For me the important authority that a data scientist brings to the team is the ability to improve product conversations with ‘data thinking’ as Monica Rogati suggests. We can make data thinking a natural part of product decisions, in order to reduce the sort of data literacy problems highlighted above.
[In the original talk the final two slides had references to “data” instead of “data thinking”.]
Summary
 To recap, I think there's a lot of value in bringing data scientists into your balanced team. This helps make data thinking a central part of the product conversation. The data scientist has the obligation to provide data insights and explore potential uses, all in service to the team. In effect we are trying to break down the walls between data scientists and the rest of the product team.
To recap, I think there's a lot of value in bringing data scientists into your balanced team. This helps make data thinking a central part of the product conversation. The data scientist has the obligation to provide data insights and explore potential uses, all in service to the team. In effect we are trying to break down the walls between data scientists and the rest of the product team.
Thank you to all the great people I’ve worked with as we’ve learned how data science contributes as part of a product team, from Pivotal and our client teams. In particular, I want to thank Janice Fraser for allowing me to reuse and adapt material from her Balanced Team talk slide-deck.
I hope that this is only the start of the conversation about Data Science in the Balanced Team and I look forward to hearing how data scientists are making ‘data thinking’ a central part of their product team’s work.